
RAG (Retrieval-Augmented Generation) er en metode, der gør AI-assistenter som i Promte skarpere, fordi de kan hente opdateret viden fra dokumenter i realtid. Men RAG har sine udfordringer: Den fungerer bedst til præcise opslag, mens f.eks. komplekse analyser i flere steps og aggregeringer ofte giver problemer med RAG og kræver andre eller supplerende metoder.
Vi har for nyligt arbejdet på en case med en kommune, som ville bruge en Promte AI-assistent til at gennemgå alle udvalgsmødereferater fra de seneste år til at finde ud af, hvem der oftest melder afbud til møderne. Referaterne var i tekstformat, og oplysningerne om afbud stod et eller andet sted i teksten. Nogle gange var det formuleret som “Hans Jørgen var fraværende”, andre gange som “Afbud fra H.J.”. Kommunen forestillede sig, at AI-assistenten nemt kunne "trawle" alle referaterne og lave en pæn oversigt.
Men det virker ikke (med almindelig RAG i hvert fald). Problemet er, at LLMs (AI-modeller, der genererer tekst) kun kan forholde sig til en begrænset mængde tekst ad gangen, og at man derfor opdeler dokumenter i bidder ("chunks") for at kunne hente information ud af dem. Det betyder, at modellen ikke har det fulde overblik. Den kan finde enkelte møder, hvor der var afbud, men den kan ikke scanne alle referater og udregne, hvem der har meldt mest afbud.
Et spørgsmål, den sagtens ville kunne svare på kunne altså være, “Deltog Hans Jørgen på udvalgsmødet d. 8. april i år?”, mens den ville have sværere ved at svare korrekt på “Hvor mange gange har Hans Jørgen meldt afbud de seneste to år?”. Det er et godt eksempel på, at RAG godt nok virker rigtig godt til mange AI-brugsscenarier, men bestemt også har sine begrænsninger.
Lad os tage et nærmere kig på, hvad RAG-baserede assistenter er gode til - og knap så gode til, så man kan træffe en kvalificeret beslutning om, hvorvidt et brugsscenarie er godt til RAG-baserede AI-assistenter, eller om man skal forsøge at løse den med en anden teknologi. Først skal vi lige have styr på et par grundlæggende begreber…
En LLM er et neuralt netværk, som har lært at forudsige det næste ord i en sætning baseret på milliarder af teksteksempler. Den “ved” ikke noget i klassisk forstand, men den har et ekstremt detaljeret statistisk kort over, hvordan sprog bruges, og kan dermed svare plausibelt på stort set alle spørgsmål. ChatGPT er et velkendt eksempel. LLM'er er dygtige til at skrive flydende og give generelle svar, men mangler ofte adgang til specifik og opdateret viden.
RAG er en teknik, der kombinerer en LLM med en søgefunktion i en dokumentbase eller en anden datakilde, som man stoler på kan sikre korrekt information. Idéen er at hente relevant information fra dine egne dokumenter (f.eks. lokale filer, tekster fra et intranet eller en hjemmeside eller lovtekster), som kan gives med som kontekst, når LLM'en genererer svar. RAG gør det muligt at:
Tilføje opdateret og domænespecifik viden (f.eks. vejledninger, lovgivning eller interne dokumenter)
Gøre svar mere faktuelt korrekte og reducerer hallucinationer i LLM’er
Undgå dyre omtræninger af LLM'er
Tilføje kildehenvisninger til svar for bedre transparens
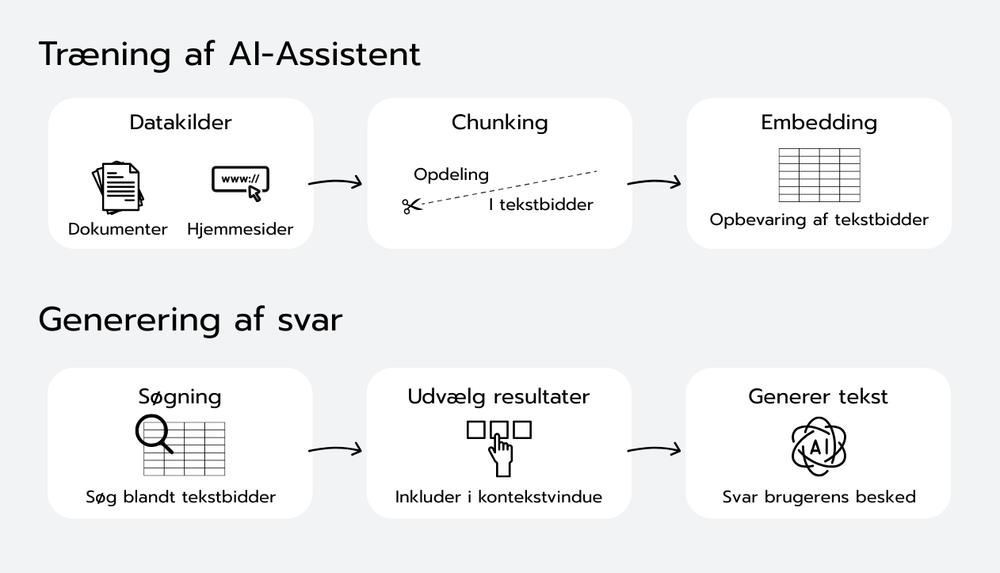
Helt lavpraktisk sendes der altså tekstbidder fra dokumenterne, der er indlæst, til LLM’en sammen med den besked en bruger har sendt. LLM’en kigger så samtidigt på brugerens besked og tekstbidderne, og genererer et svar til brugeren baseret på tekstbidderne.
LLM’er har dog en begrænsning for, hvor meget tekst de kan modtage som input til den besked, den skal generere. Derfor er man nødt til at begrænse mængden af tekst man sender til dem.
Denne grænse kaldes kontekstvinduet og måles i tokens (orddele). Tidlige versioner af LLM’er havde plads til cirka 2.048 tokens (ca. 8.000 tegn og 1.500 ord), mens nyere modeller i princippet kan håndtere langt mere, men altid med en begrænsning. F.eks. kan GPT-4o håndtere 128.000 tokens (ca. 512.000 tegn og 96.000 ord), mens nogle af Gemini-modeller fra Google kan håndtere 1 million tokens (ca. 4.000.000 tegn og 750.000 ord) (performance til at finde specifik information i meget store tokens-mængder falder dog, og det er derfor stadig en god idé at begrænse antal tokens i kontekstvindue, selv hvis modellen kan håndtere mange tokens - og man i øvrigt ikke vil spare på ressourcerne til at håndtere mange tokens pr. besked). Selv med større vinduer skal man derfor prioritere, hvad man sender til en LLM for at generere en besked.
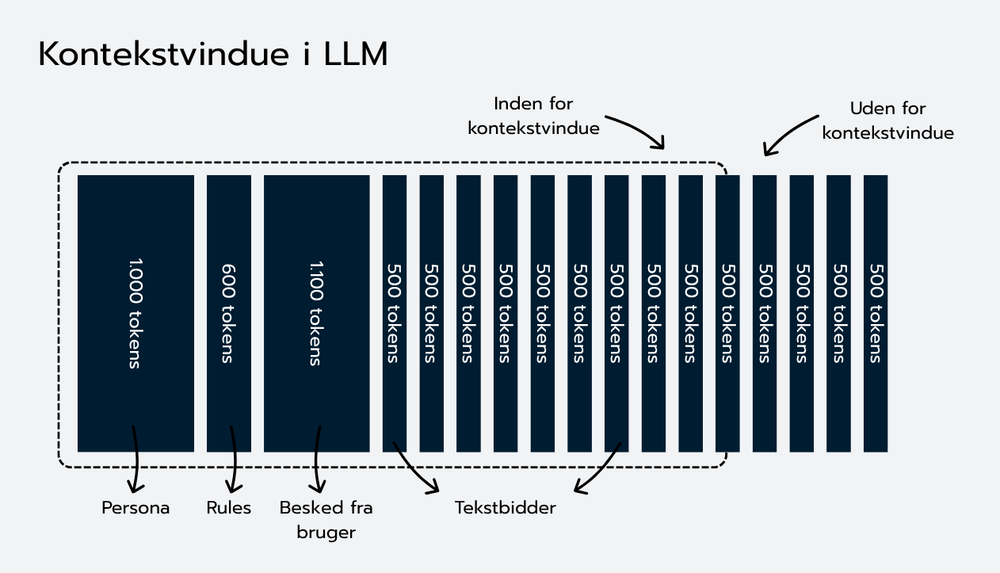
Man vil altså gerne sikre sig, at man sender en optimal mængde tekst til LLM’en i dens kontekstvindue, sådan at den kan besvare brugerens spørgsmål med specifik og opdateret viden uden at overskride kontekstvinduet. Lidt forsimplet gøres det ved at:
Dele dokumenter op i segmenter (chunks).
Omsætte dem til "embeddings" (matematiske repræsentationer af teksten).
Gemme dem i en søgbar vektor-database.
Når brugeren stiller et spørgsmål, beregnes en embedding af spørgsmålet, og de mest relevante chunks findes og gives som input til LLM'en.
Få LLM’en til at generere et svar til brugeren på baggrund af disse søgeresultater.
RAG gør det på den måde muligt for en AI-assistent at hente viden direkte fra eksterne dokumenter, når den svarer. I stedet for at basere sig udelukkende på sin generelle træning, bruger modellen relevante bidder af tekst som dokumentation. Det giver svar, der er mere faktuelle, præcise og nemmere at kontrollere som administrator af en AI-assistent.
En stor fordel ved RAG er, at du kan ændre eller opdatere kilderne uden at ændre selve AI-modellen. Dermed bliver det både hurtigt, billigt og fleksibelt at holde viden opdateret. RAG egner sig især godt til spørgsmål, hvor svaret kun findes i små, specifikke dele af dokumenter (f.eks. en lovtekst eller en vejledning til et IT-system).
Alligevel har metoden visse udfordringer. Fordi dokumenterne skal deles op i mindre tekstbidder, kan man miste den overordnede sammenhæng, hvis opdelingen foretages uhensigtsmæssigt. For små bidder giver en fragmenteret forståelse, mens for store eller for mange bidder hurtigt fylder hele kontekstvinduet i modellen.
Derudover kan RAG have svært ved komplekse forespørgsler, der kræver, at modellen tæller eller aggregerer oplysninger på tværs af flere dokumenter, f.eks.: “Hvem har meldt flest afbud til møder det seneste år?”.
PDF-filer med lange lister eller komplekse tabeller udgør også et problem, fordi LLM’er typisk læser tekst sekventielt. Når data spredes ud over flere chunks, går struktur og relationer nemt tabt, hvilket reducerer kvaliteten af svarene. Her er løsningen først at omdanne lister og tabeller til strukturerede data, før RAG anvendes.
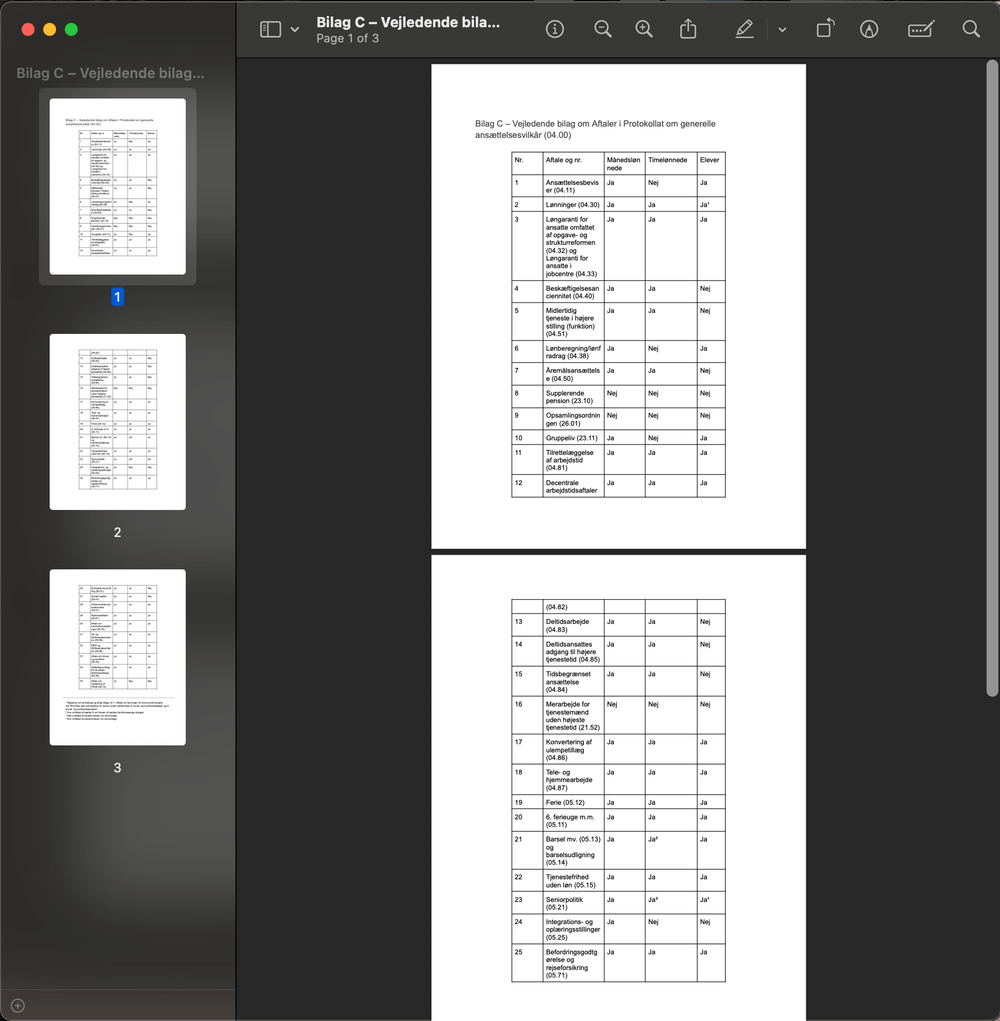
Eksempel på PDF, hvor tabel strækker sig over flere sider. Her vil en LLM have svært ved at forstå f.eks. Hvad “24” eller “ja” betyder på side 2, fordi overskriften på kolonnen står på en anden side.
Hvordan løser vi det i Promte? Hos Promte har vi udviklet en proces, hvor dokumenter automatisk opdeles i bidder og optimeres med såkaldte embeddings. Teksterne forbehandles for at bevare sammenhæng, overskrifter og struktur. Når assistenten modtager et spørgsmål, finder vi de mest relevante bidder og indsætter dem i modellens kontekstvindue sammen med instruktioner og brugerens forespørgsel.
En god måde at tænke kontekstvinduet på er som et “budget” af plads: Hvis vinduet eksempelvis rummer 16.000 tokens, kan du reservere omkring 2.000 tokens til modellens svar, 1.000 til instruktioner og brugerspørgsmålet, hvilket efterlader ca. 13.000 tokens til dokumentbidder. Ved 500 tokens pr. dokumentbid giver det plads til mellem 4 og 20 bidder afhængigt af øvrige elementer.
Ved opgaver, hvor der kræves sammenligninger eller beregninger på tværs af flere filer, bør RAG suppleres med struktureret dataudtræk og en form for databehandling (eksempelvis via SQL eller andre databaseværktøjer).
Fordele ved RAG-metoden | Begrænsninger ved RAG-metoden |
|
|
Det er vigtigt at kende de forskellige strategier, man kan anvende til at håndtere begrænsningerne ved AI-assistenter baseret på RAG.
Første trin er altid at forstå, hvad du faktisk ønsker at opnå med AI-assistenten. Skal den finde enkelte fakta, eller skal den aggregere og analysere store datamængder? RAG er ideel til konkrete opslag efter enkeltoplysninger, men ikke velegnet til mere komplekse opgaver, hvor du eksempelvis skal tælle, summere eller sammenligne oplysninger på tværs af flere dokumenter.
For at finde ud af, om RAG er den rette metode, er det vigtigt at skelne mellem to grundlæggende typer af forespørgsler: lookup og aggregering.
Lookup-spørgsmål handler om at finde en specifik oplysning, ofte placeret i ét dokument eller en afgrænset del af et dokument. Her fungerer RAG særdeles godt, fordi systemet hurtigt kan hente præcise tekstbidder selv i meget store mængder data, som LLM’en derefter bruger som kilde.
Eksempel:
“Hvem har meldt afbud til udvalgsmødet d. 3. marts?”
Her er RAG ideel, fordi svaret typisk findes direkte i et bestemt dokument eller afsnit.
Aggregeringsspørgsmål kræver, at assistenten sammenstiller oplysninger fra mange forskellige dokumenter eller kilder. Her handler det om beregninger, optællinger eller statistiske analyser. Dette er RAG ikke godt til alene, fordi modellen ikke har mulighed for at holde styr på store mængder data på én gang.
Eksempel:
“Hvem har meldt flest afbud til udvalgsmøderne i hele 2023?”
I dette tilfælde er der brug for en struktureret tilgang, hvor data først trækkes ud af dokumenterne og organiseres, hvorefter et analyseværktøj som SQL eller Excel kan give et præcist og pålideligt svar.
Løsninger til brugsscenarier, der egner sig dårligt til simpel RAG
Her er nogle mulige løsninger til brugsscenarier, der på overfladen egner sig dårligt til en simpel RAG-AI-assitent:
Kombinér RAG med strukturerede data: Hvis opgaven kræver sammenligninger eller numeriske beregninger, kan du med fordel kombinere RAG med strukturerede data som SQL-databaser eller regneark. Det indebærer, at du først konverterer tekst til struktureret data og derefter udfører forespørgsler eller analyser direkte på disse data. På denne måde udnytter du styrkerne ved både RAG og struktureret databehandling.
Opdel komplekse forespørgsler i mindre dele: Store og komplicerede spørgsmål kan ofte med fordel deles op i flere mindre underspørgsmål. Du kan eksempelvis definere søgegrupper eller kategorier, hente resultater separat for hver gruppe og derefter samle svarene. Dette kan enten være en manuel proces, hvor man opdeler brugsscenariet i forskellige spørgsmål eller måske endda i forskellige AI-assistenter, eller det kan løses teknisk ved at sikre, at AI-assistenten kan foretage flere forespørgsler. Det gør det muligt at holde sig inden for modellens begrænsninger og sikrer samtidig, at intet vigtigt går tabt.
Anvend specialiserede metoder til tabeller og lister: Tabeller og lange lister kræver ekstra opmærksomhed, da disse formater ofte bliver fragmenteret, når dokumenter opdeles i chunks. Her er det nødvendigt med korrekt preprocessing: tabeller skal udtrækkes og struktureres, så overskrifter entydigt kobles til deres værdier. Denne ekstra preprocessing sikrer, at LLM’en bedre forstår strukturen, hvilket forbedrer kvaliteten af svarene væsentligt.
I en Promte-assistent gør vi mange ting for at optimere på, hvordan vi sender kontekst til AI-modellen. Men som udgangspunkt benytter den relativt simple RAG-metoder. Vi har dog erfaringer med at alle de tre ovenstående metoder for at løse nogle af udfordringerne med RAG. Tag derfor fat i Promte, hvis du har et godt brugsscenarie, hvor der er brug for mere avancerede metoder i kombination med RAG for at få AI-assistenten til at virke.
RAG er en stærk metode til at gøre generativ AI mere præcis og faktuelt korrekt. Men det kræver, at man er opmærksom på både styrker og begrænsninger. Metoden virker bedst til opslag af enkeltstående fakta, hvor kun en begrænset mængde information skal findes frem (gerne blandt meget store mængder data), mens komplekse analyser og aggregeringer typisk kræver andre teknologier eller en kombination af RAG og strukturerede databehandlingsværktøjer.
Hos Promte bygger vi effektive AI-assistenter ved hjælp af RAG, men vi er også klar til at rådgive, hvornår RAG bør suppleres eller erstattes af andre løsninger. Vi håndterer alle de praktiske udfordringer med chunking, præcis tekstbehandling, tabeller og kildehenvisninger, og vores platform kan nemt integreres med strukturerede forespørgsler.
Er du interesseret i at bruge AI smartere og mere effektivt i din organisation, så kontakt os. Vi hjælper gerne med at finde den bedste løsning til netop jeres behov.