
Hvordan er det med ChatGPT og de data, du føder ind i det? Lærer den af de samtaler, du som bruger har med den? Dette blogindlæg har til formål at afmystificere nøglespørgsmål omkring ChatGPT og fokuserer specifikt på, hvordan det lærer og dets dataforbrug. Lad os komme i gang!
Det korte svar: Nå, ja, måske og nej. For det meste nej.
Lad os dele spørgsmålet op i to emner for at se, hvordan det fungerer. Først kan vi se på, om ChatGPT løbende lærer af den samtale, det har med brugerne. Det er her svaret "for det meste nej" kommer fra. For det andet kan vi se på, hvordan OpenAI, virksomheden bag ChatGPT, potentielt kan bruge samtalerne til at forbedre deres sprogmodeller i fremtiden. Det er her "ja, måske" kommer i spil.
Det korte svar: Nej.
Det lange svar kræver, at vi ser lidt på, hvordan ChatGPT og de bagvedliggende sprogmodeller fungerer. ChatGPT bruger enten GPT-3.5 eller GPT-4 til at generere svarene på brugernes spørgsmål eller samtale. "GPT" er en forkortelse for Generative Pre-trained Transformer. "Foruddannet" er nøgleordet her.
Udtrykket "foruddannet" betegner den fase, hvor modellen i første omgang trænes på et massivt korpus af internettekst, herunder en masse åbent tilgængelige tekster samt licenserede tekststykker i tilfælde af GPT-4. Denne fortræningsproces gør det muligt for GPT-3.5 eller GPT-4 at forstå nuancerne af sprog og kontekst ved at forudsige det næste ord i en sætning baseret på de mønstre, det genkender fra den store mængde data, det blev trænet på.
En almindelig misforståelse om AI-modeller som ChatGPT er, at de lærer og forbedrer sig over tid fra input og output af deres interaktioner med brugere. Dette er dog ikke tilfældet. Når først fortræningsfasen er afsluttet, lærer eller tilpasser disse modeller sig ikke fra brugerinteraktioner eller input. I stedet genererer de svar baseret på de mønstre og den viden, de har lært i løbet af denne indledende træningsfase. Modellerne har ingen hukommelse om tidligere interaktioner, gemmer ikke personlige data og forbedres ikke over tid baseret på de samtaler, de har. Dette er et afgørende punkt at forstå, når man overvejer funktionaliteten af ChatGPT og andre AI-sprogmodeller (det kan du læse mere om her eller her).
ChatGPT har altså kun sin viden fra sin fortræning samt den kontekst, du giver den som bruger i en given samtale. Det behøver du ikke bekymre dig om. Men noget du måske skal bekymre dig om er, hvordan OpenAI træner sine fremtidige sprogmodeller. Lad os se på det…
Det korte svar: Ja, og selvom de ikke vil, skal du nok passe på!
Når du logger ind på ChatGPT, bliver du mødt af en skærm, der siger: "Samtaler kan blive gennemgået af vores Al-trænere for at forbedre vores systemer. Del venligst ikke nogen følsomme oplysninger i dine samtaler."
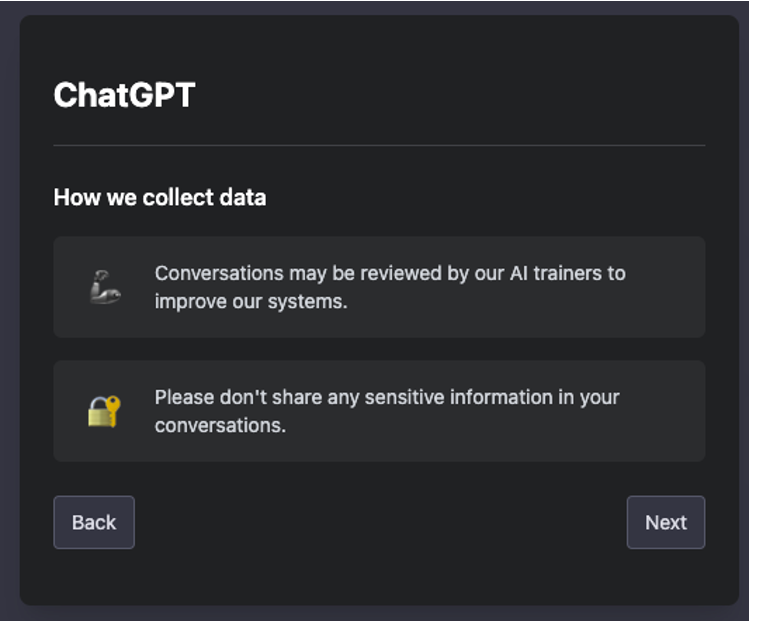
Så de kan se i dine samtaler. Og hvis man ser lidt længere ind i deres vilkår for brug (det gjorde du nok ikke, men det gjorde jeg, så det behøver du ikke) du finder denne del:
(c) Brug af indhold til at forbedre tjenester. Vi bruger ikke indhold, som du leverer til eller modtager fra vores API ("API-indhold") til at udvikle eller forbedre vores tjenester. Vi kan bruge indhold fra andre tjenester end vores API ("Ikke-API-indhold") til at hjælpe med at udvikle og forbedre vores tjenester. Du kan læse mere her om, hvordan ikke-API-indhold kan bruges til at forbedre modellens ydeevne. Hvis du ikke ønsker, at dit ikke-API-indhold skal bruges til at forbedre tjenesterne, kan du framelde dig ved at udfylde denne formular. Bemærk venligst, at dette i nogle tilfælde kan begrænse vores Tjenesters mulighed for bedre at håndtere din specifikke brugssag.
Source: https://openai.com/policies/terms-of-use. Du kan også læse mere om, hvordan OpenAI bruger samtalerne til at forbedre deres modeller her.
Dette er skrevet på juridisk sprog, men brugen af ChatGPT falder ind under "Non-API Content"-bøtten, hvilket betyder, at samtaler du har med ChatGPT potentielt kan bruges til at forbedre systemet. Processen med at "forbedre systemet" kunne indebære to ting.
Den første mulighed kaldes i processen forstærkningslæring med menneskelig feedback (RLHF). Dette er en del af trænings- og optimeringsprocessen af store sprogmodeller. Som nævnt kommer kernen i "viden" om GPT-3.5 og GPT-4 fra de store mængder tekst, den er blevet fodret med i sin indledende træning.
Efter at AI'en er blevet fodret med en enorm mængde tekster og i sig selv identificeret relevante mønstre om sprog, fysik, økonomi og så videre, deltager menneskelige AI-trænere i samtaler og spiller både bruger- og AI-assistentrollerne. Trænere giver også vurderinger for forskellige modelgenererede svar for at vejlede AI i indlæringskvalitetssvar. Disse indledende dialogdata blandes med resten af træningsdataene og danner et datasæt, som modellen kan lære af.
AI-modellens adfærd finjusteres derefter ved hjælp af en metode kaldet Proximal Policy Optimization, mens modellen også periodisk rangeres og vurderes af menneskelige AI-trænere for at skabe en belønningsmodel for forstærkningslæring. Denne iterative proces med konstant feedback, forstærkning og finjustering hjælper med at træne AI til at reagere på en mere menneskelignende og nyttig måde.

Også selvom OpenAI ikke direkte oplyser hvordan de bruger brugernes samtaler med ChatGPT, er det meget sandsynligt, at de samler nogle af læringerne fra samtalerne og bruger dem til at forstå, hvordan man kan forbedre forstærkningslæringsprocessen. Det betyder ikke, at modellen får ny viden eller information fra de samtaler, brugerne har, men derimod, at modellen bedre forstår, hvordan man besvarer spørgsmål, hvordan man er høflig på den rigtige måde, og så videre.
Det er en mulig måde at forbedre modellen på. En anden mulig anvendelse af brugernes samtaler med ChatGPT er at forbedre fremtidige sprogmodeller (f.eks. GPT-5).
Den anden måde, brugersamtaler kan bruges på, er at forbedre fremtidige sprogmodeller, som en potentiel GPT-5 eller mere. Denne proces er mere indirekte end RLHF-metoden, men kan stadig bidrage væsentligt til kvaliteten af svarene fra AI.
Når man træner en ny model, er de anvendte data typisk et massivt kompendium af offentligt tilgængelig tekst, herunder bøger, artikler, hjemmesider og mere. Disse data er i bund og grund den 'videnbase', hvorfra AI genererer sine svar. Hvis OpenAI besluttede at bruge aggregerede og anonymiserede data fra brugersamtaler med ChatGPT, kunne det potentielt være en del af træningssættet til en fremtidig model.

Dette betyder ikke, at AI'en ville 'huske' specifikke samtaler eller være i stand til at linke dem tilbage til individuelle brugere. Processen med at træne en model involverer at fodre den med milliarder af tekstord, som den derefter bruger til at lære mønstre i sprog, kontekst og svar. Dette enorme hav af tekst er anonymiseret og aggregeret, så modellen har intet kendskab til de enkelte kilder.
Der er dog et legitimt spørgsmål, der skal stilles om kvaliteten af data, der kan hentes fra brugersamtaler med ChatGPT. Selvom disse dialoger bestemt afspejler en bred vifte af emner og samtalestile, er de også i sagens natur skæve af platformens natur. Mange brugere engagerer sig i ChatGPT til formål såsom skrivehjælp, faktuelle forespørgsler, hypotetiske scenarier eller endda bare tilfældige drillerier af nysgerrighed. Selvom disse interaktioner er forskellige, repræsenterer de muligvis ikke nøjagtigt hele spektret af menneskelig dialog og kontekst.
Desuden kan samtaler med en AI være tilbøjelige til visse typer af svar eller emner, som typisk ikke ville dukke op i menneske-til-menneske-dialoger. Følgelig kan sådanne data indføre skævheder eller begrænsninger i træningssættet. I betragtning af disse potentielle ulemper kan man undre sig over, om OpenAI virkelig ville finde værdi i at bruge denne type data til modeltræning, eller om de ville vælge et mere kurateret og afbalanceret datasæt hentet fra andre kilder.
Derudover er der et vigtigt spørgsmål om cirkulariteten ved at bruge en sprogmodel til at træne en anden. Da ChatGPT i sig selv er et produkt af maskinlæringsalgoritmer og massive træningsdatasæt, kan udnyttelse af de interaktioner, det genererer til videre træning, føre til en slags feedback-loop. Kunne dette resultere i sammensatte fejl eller skævheder, der var til stede i den oprindelige model? Eller kan det føre til opretholdelsen af visse reaktionsmønstre, hvilket resulterer i et tab af mangfoldighed i, hvordan AI'en interagerer? Det er i det væsentlige at bruge en AI's forståelse af sprog - som, selvom det er imponerende, stadig er fundamentalt forskellig fra menneskelig forståelse - til at videreuddanne en AI. Dette kunne tænkes at begrænse potentialet for den nye model til at udvikle sig ud over dens forgængers muligheder og begrænsninger. Så det er - i hvert fald efter min mening - ret tvivlsomt, om OpenAI ville få nogen større fordele ved at bruge tidligere samtaler med ChatGPT til at træne fremtidige sprogmodeller sammenlignet med at finde andre træningsmaterialer af højere kvalitet såsom licenseret materiale fra bøger, aviser eller magasiner, for blot at nævne nogle få.
For at afslutte de seneste sektioner kunne OpenAI potentielt bruge brugernes samtaler med ChatGPT, f.eks. at forbedre deres eksisterende modeller i RLHF-processen eller som træningsmateriale til fremtidige sprogmodeller (ud over GPT-4). Selvom jeg ikke ser disse to muligheder som meget sandsynlige, tillader du, når du accepterer vilkårene fra OpenAI, i det mindste OpenAI at gemme indholdet af dine samtaler og mennesker til at kigge i dine samtaler. Og det kan være et problem i sig selv, især hvis du har at gøre med meget personlige eller meget fortrolige oplysninger.
At sende fortrolige oplysninger til tredjepartsværktøjer bør sandsynligvis afholdes fra i alle tilfælde. Store virksomheder som Samsung, Apple, Verizon, JPMorgan og mange flere, der erkender disse risici, har derfor begrænset deres ansatte i at bruge disse tjenester. Og hvis du har med noget meget fortroligt at gøre, såsom kildekoden til vigtig software i store organisationer, er værktøjer som ChatGPT, selvom de er utrolig nyttige, måske ikke passende.
Okay, men hvad kan du så gøre ved det? Skal man bare helt undgå at bruge AI-værktøjer som ChatGPT, hvis man arbejder med følsomme data? Heldigvis er der nogle ganske nemme ting, du kan gøre for at mindske risikoen for at lække følsomme oplysninger, når du arbejder med AI-værktøjer. En mulighed er at fjerne de fortrolige dele af den tekst, du vil sende til ChatGPT, før du sender den. En anden mulighed er at fravælge at få dine beskeder gemt i ChatGPT, da dette faktisk nemt gøres. Til sidst kan du overveje at anskaffe dig din egen chatbot, hvor du styrer data, lagring og så videre.
Før du sender nogen information til en sprogmodel som ChatGPT, skal du overveje at rense følsomme oplysninger lokalt. Typisk er det store flertal af et stykke tekst eller andre datapunkter faktisk ikke fortrolige eller personlige. Ved at erstatte de få stykker af teksten, der indeholder den fortrolige information, med dummy-data, kan du uden problemer bruge værktøjer som ChatGPT.
OpenAI gjorde det for nylig muligt at fravælge at få samtalerne gemt. Disse nye kontroller gør det muligt for brugere at slå deres chathistorik fra og derved fravælge deres samtalehistorik som data til træning af AI-modeller.
Disse nye kontroller, som er tilgængelige for alle ChatGPT-brugere, kan findes i ChatGPT-indstillingerne. For samtaler indledt med chathistorik deaktiveret, vil disse hverken blive brugt til træning og forbedring af ChatGPT-modellen, og de vil heller ikke blive vist i historiesidebjælken. På trods af dette vil OpenAI opbevare disse samtaler internt i en periode på 30 dage og kun gennemgå dem efter behov for at overvåge for misbrug, før de slettes permanent.
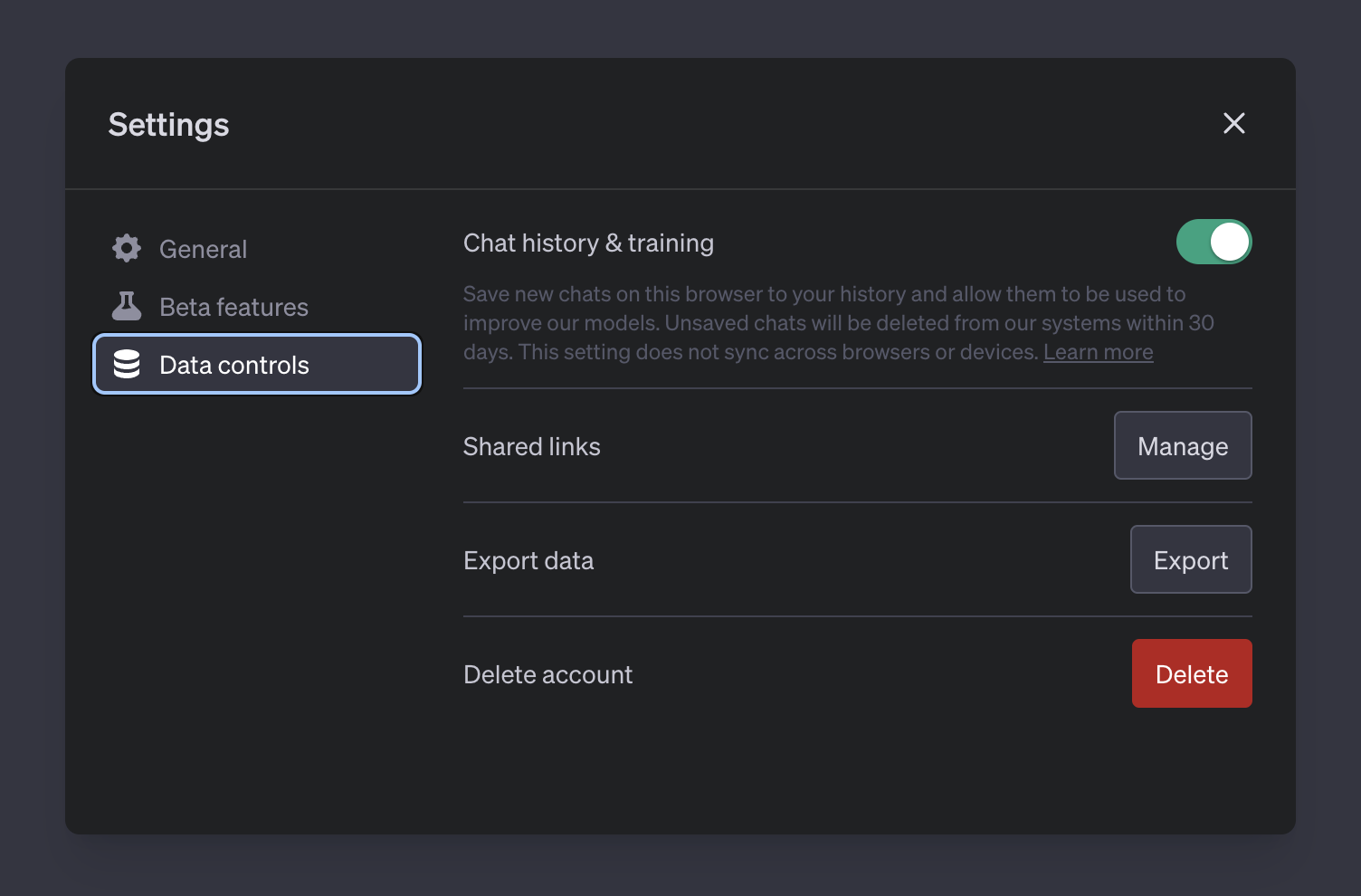
Brugere, der vælger at fravælge at give deres data til OpenAI til træningsformål, vil dog ikke kunne bruge samtalehistorik-funktionen, så du vil miste muligheden for at gå tilbage i gamle samtaler, hvis du vælger at fravælge samtalelagring.
Hvis din virksomhed er særligt interesseret i at udnytte AI's muligheder, men du har bekymringer om fortrolighed og kontrol med data, er der en anden løsning: Applai Chat. Applai Chat giver organisationer deres egen tilpassede AI-drevne chatbot, baseret på samme grundlag som ChatGPT.
- "Åh, så Victor, du skrev alt dette kun for at fortælle om din egen chatbot?"
Nå, ikke kun for at fortælle dig om vores chatbot-løsning (som i øvrigt er rigtig cool!). Men nu hvor jeg har din opmærksomhed...
En af de mest attraktive funktioner ved Applai Chat er det faktum, at din virksomhed bevarer fuld kontrol over dataene. Du bestemmer, hvilken information chatbotten har adgang til, hvordan den opbevares, og hvor den bruges. Denne tilgang passer perfekt til organisationer, der prioriterer databeskyttelse og sikkerhed højt, hvilket giver ro i sindet, samtidig med at de høster fordelene ved AI-teknologi.
Men fordelene stopper ikke der. Applai Chat kan også kobles op med din virksomheds egne datakilder. Dette inkluderer ressourcer såsom dit websted, intern dokumentation, vidensbase og mere. Ved at gøre dette kan Applai Chat lære af disse ressourcer og levere mere præcise og kontekstuelt nøjagtige svar. Resultatet? En chatbot, der ikke kun forstår sproget på ChatGPT-niveau, men som også har indgående kendskab til din specifikke virksomhed, branche eller kundebase.
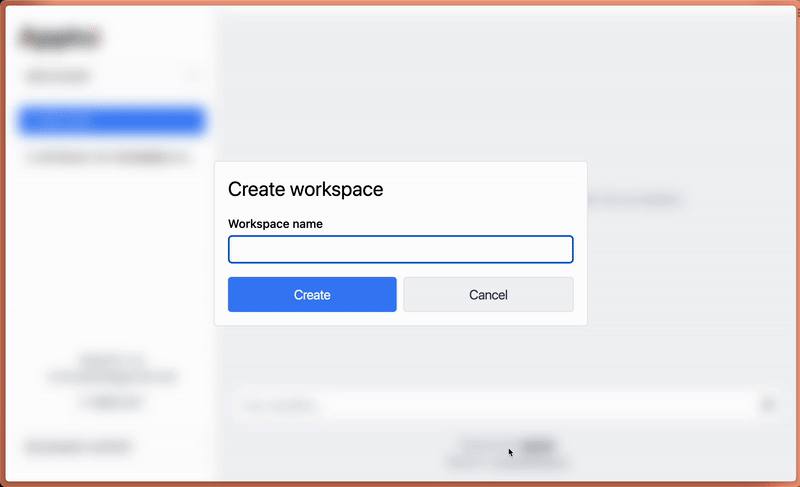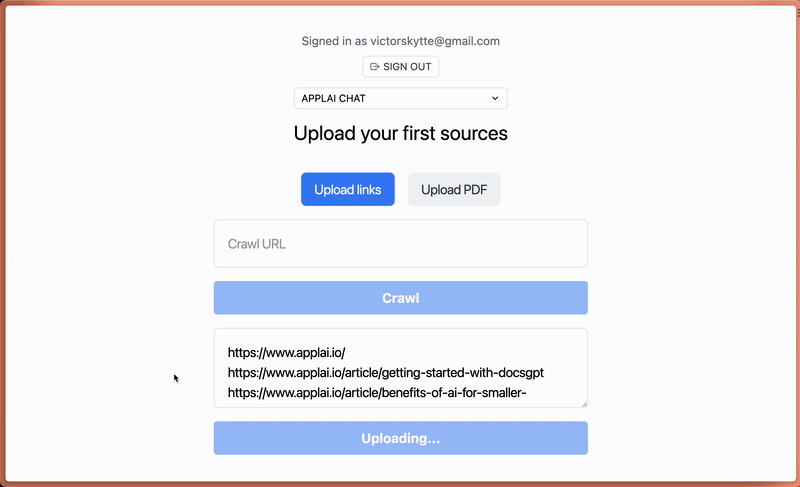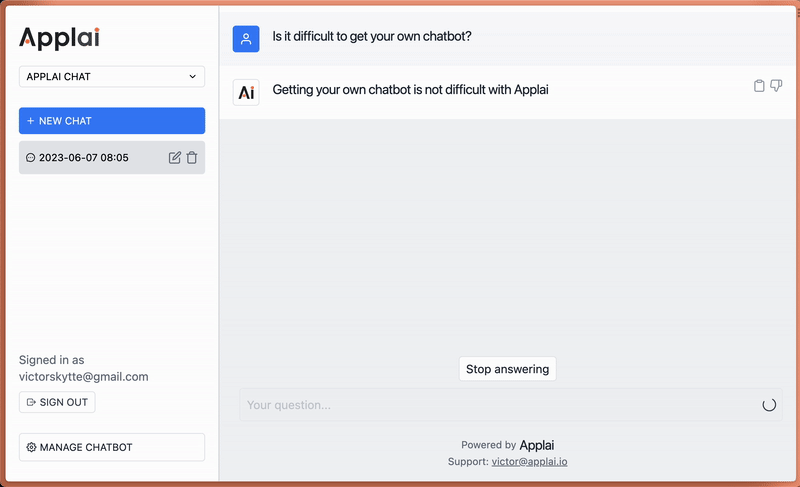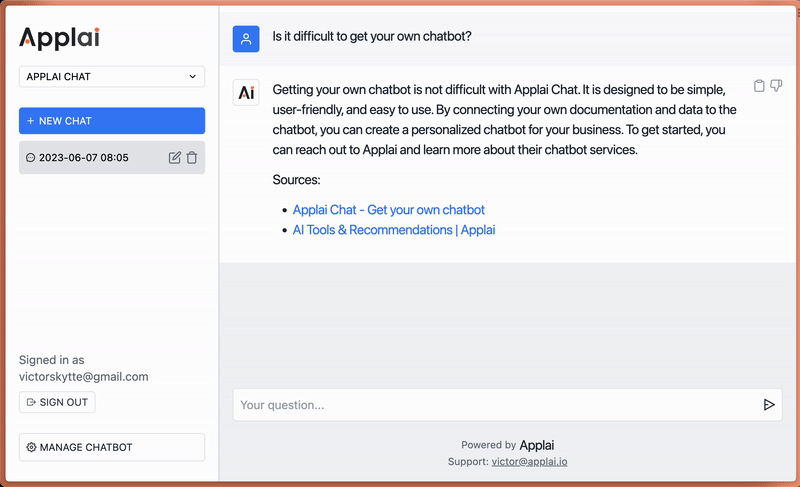
Så hvordan fungerer det i praksis? Forestil dig, at en kunde spørger din Applai Chat-drevne bot om en bestemt funktion ved dit produkt. I stedet for at give et generisk svar, kunne botten trække på sin viden om din produktdokumentation og hjemmeside for at give et detaljeret, præcist svar. Eller en medarbejder kan spørge om en bestemt intern proces, og botten, der trækker fra din interne videnbase, kan guide dem trin for trin gennem proceduren. Det er som at have ChatGPT, men skræddersyet med dine egne data.
I Applai vejleder vi både virksomheder i, hvordan de kan bruge AI til deres arbejde på en smart måde samt udvikler skræddersyede AI-løsninger som Applai Chat, så du er meget velkommen til at tage fat, hvis du har lyst til at høre mere eller har spørgsmål. Kontakt os her.