
RAG (Retrieval-Augmented Generation) is a method that makes AI assistants like in Promte sharper because they can retrieve updated knowledge from documents in real time. But RAG has its challenges: It works best for precise postings, while e.g. complex analyzes in several steps and aggregations often cause problems with RAG and require other or supplementary methods.
We recently worked on a case with a municipality that wanted to use a Promte AI assistant to review all committee meeting minutes from recent years to find out who most often cancels the meetings. The minutes were in text format, and the information about cancellation was somewhere in the text. Sometimes it was worded as "Hans Jørgen was absent", other times as "Rejection from H.J.". The municipality imagined that the AI assistant could easily "traw" all the minutes and create a neat overview.
But it doesn't work (at least with regular RAG). The problem is that LLMs (AI models that generate text) can only deal with a limited amount of text at a time, and that you therefore divide documents into chunks in order to extract information from them. This means that the model does not have the full overview. It can find individual meetings where there were cancellations, but it cannot scan all minutes and calculate who has reported the most cancellations.
A question it would easily be able to answer could therefore be, "Did Hans Jørgen attend the committee meeting on 8 April this year?", while it would have more difficulty answering correctly "How many times has Hans Jørgen canceled in the past two years?". It's a good example of RAG working really well for many AI usage scenarios, but certainly also has its limitations.
Let's take a closer look at what RAG-based assistants are good at - and not so good at, so you can make an educated decision about whether a use case scenario is good for RAG-based AI assistants, or whether you should try to solve it with another technology. First, we need to get a handle on a few basic concepts...
An LLM is a neural network that has learned to predict the next word in a sentence based on billions of text samples. It doesn't "know" anything in the classical sense, but it has an extremely detailed statistical map of how language is used, and can thus plausibly answer virtually any question. ChatGPT is a well-known example. LLMs are adept at writing fluently and providing general answers, but often lack access to specific and up-to-date knowledge.
RAG is a technique that combines an LLM with a search function in a document base or other data source that can be trusted to ensure correct information. The idea is to retrieve relevant information from your own documents (eg local files, texts from an intranet or a website or legal texts) which can be provided as context when the LLM generates answers. RAG makes it possible to:
Add up-to-date and domain-specific knowledge (e.g. guidance, legislation or internal documents)
Making answers more factually correct and reducing hallucinations in LLMs
Avoid expensive retraining of LLMs
Add citations to answers for better transparency
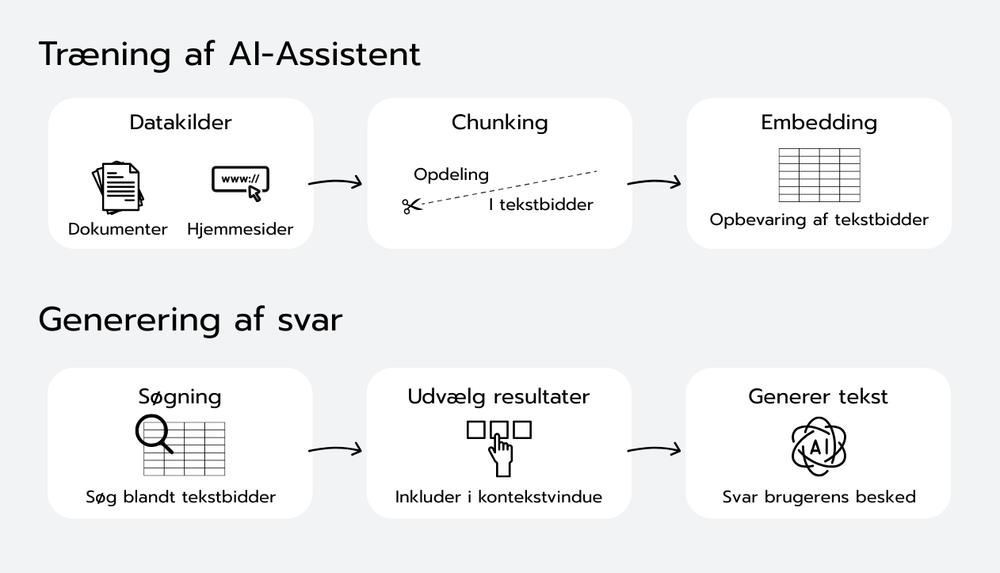
In a completely impractical way, chunks of text from the documents that have been loaded are sent to the LLM together with the message a user has sent. The LLM then simultaneously looks at the user's message and the text chunks, and generates a response to the user based on the text chunks.
However, LLMs have a limit on how much text they can receive as input for the message it must generate. Therefore, you have to limit the amount of text you send to them.
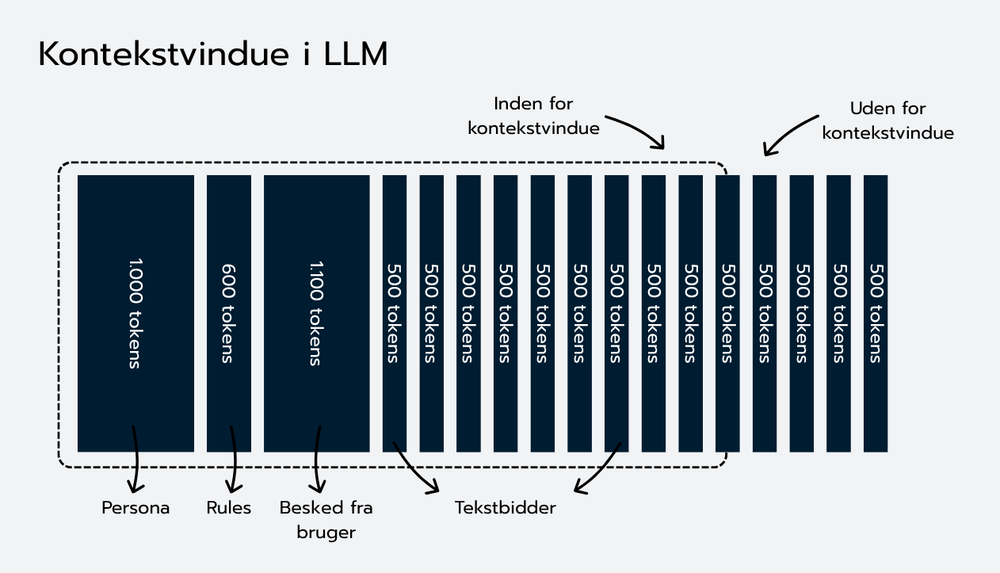
This limit is called the context window and is measured in tokens. Early versions of LLMs had room for approximately 2,048 tokens (approximately 8,000 characters and 1,500 words), while newer models can in principle handle much more, but always with a limitation. For example GPT-4o can handle 128,000 tokens (approx. 512,000 characters and 96,000 words), while some of the Gemini models from Google can handle 1 million tokens (approx. 4,000,000 characters and 750,000 words) (performance to find specific information in very large amounts of tokens decreases, however, and it is therefore still a good idea to limit the number of tokens in the context window, even if the model can handle many tokens - and you don't want to save on resources to handle many tokens per message). Even with larger windows, you therefore have to prioritize what you send to an LLM to generate a message.
So you want to make sure that you send an optimal amount of text to the LLM in its context window, so that it can answer the user's questions with specific and up-to-date knowledge without exceeding the context window. In a slightly oversimplified way, it is done by:
Divide documents into segments (chunks).
Convert them to "embeddings" (mathematical representations of the text).
Store them in a searchable vector database.
When the user asks a question, an embedding of the question is calculated and the most relevant chunks are found and given as input to the LLM.
Have the LLM generate a response for the user based on these search results.
RAG thus makes it possible for an AI assistant to retrieve knowledge directly from external documents when it responds. Instead of relying solely on its general training, the model uses relevant chunks of text as documentation. It provides answers that are more factual, accurate and easier to control as an administrator of an AI assistant.
A big advantage of RAG is that you can change or update the sources without changing the AI model itself. This makes it quick, cheap and flexible to keep knowledge up to date. RAG is particularly suitable for questions where the answer can only be found in small, specific parts of documents (e.g. a legal text or instructions for an IT system).
Still, the method has certain challenges. Because the documents must be divided into smaller pieces of text, the overall context can be lost if the division is done inappropriately. Too small chunks give a fragmented understanding, while too large or too many chunks quickly fill the entire context window in the model.
In addition, RAG may have difficulty with complex queries that require the model to count or aggregate information across several documents, for example: "Who has reported the most cancellations to meetings in the past year?".
PDF files with long lists or complex tables also pose a problem because LLMs typically read text sequentially. When data is spread out over multiple chunks, structure and relationships are easily lost, reducing the quality of the answers. Here, the solution is to first transform lists and tables into structured data before RAG is used.
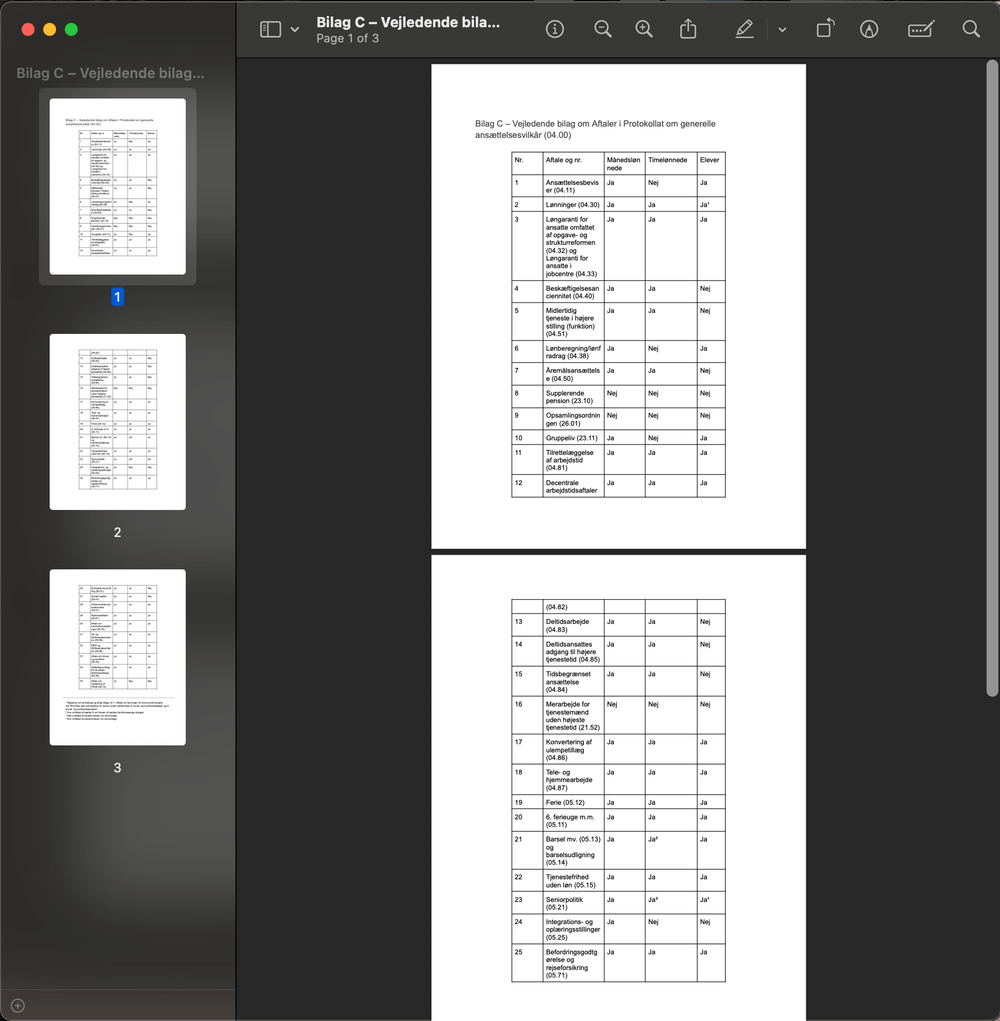
Example of PDF where table extends over several pages. Here, an LLM will have difficulty understanding e.g. What does “24” or “yes” mean on page 2 because the heading of the column is on another page.
How do we solve it in Promte? At Promte, we have developed a process where documents are automatically divided into chunks and optimized with so-called embeddings. The texts are pre-processed to preserve coherence, headings and structure. When the assistant receives a question, we find the most relevant chunks and insert them into the model's context window, along with instructions and the user's query.
A good way to think of the context window is as a “budget” of space: If the window holds, for example, 16,000 tokens, you can reserve about 2,000 tokens for the model's response, 1,000 for instructions and the user question, leaving approx. 13,000 tokens for document chunks. At 500 tokens per document bit gives it space for between 4 and 20 bits depending on other elements.
For tasks where comparisons or calculations across multiple files are required, RAG should be supplemented with structured data extraction and some form of data processing (for example via SQL or other database tools).
Advantages of the RAG method | Limitations of the RAG method |
|
|
It is important to know the different strategies one can use to deal with the limitations of AI assistants based on RAG.
The first step is always to understand what you actually want to achieve with the AI assistant. Should it find individual facts, or should it aggregate and analyze large amounts of data? RAG is ideal for specific searches for individual information, but not suitable for more complex tasks, where you need to count, sum or compare information across several documents, for example.
To determine whether RAG is the right method, it is important to distinguish between two basic types of queries: lookup and aggregation.
Lookup questions are about finding specific information, often located in one document or a defined part of a document. Here, RAG works extremely well, because the system can quickly retrieve precise pieces of text even in very large amounts of data, which the LLM then uses as a source.
Eksempel:
"Who has canceled the committee meeting on March 3?"
Here, RAG is ideal because the answer is typically found directly in a specific document or section.
Aggregation questions require the assistant to compile information from many different documents or sources. Here it is about calculations, counts or statistical analyses. RAG is not good for this alone, because the model does not have the ability to keep track of large amounts of data at once.
Eksempel:
"Who has canceled the most committee meetings throughout 2023?"
In this case, a structured approach is needed, where data is first extracted from the documents and organized, after which an analysis tool such as SQL or Excel can provide a precise and reliable answer.
Solutions for use cases that are ill-suited to simple RAG
Here are some possible solutions for usage scenarios that, on the surface, are ill-suited for a simple RAG-AI assistant:
Combine RAG with structured data: If the task requires comparisons or numerical calculations, you can advantageously combine RAG with structured data such as SQL databases or spreadsheets. This involves first converting text to structured data and then performing queries or analysis directly on that data. In this way, you utilize the strengths of both RAG and structured data processing.
Break complex queries into smaller parts: Large and complicated questions can often advantageously be divided into several smaller sub-questions. For example, you can define search groups or categories, retrieve results separately for each group and then collect the answers. This can either be a manual process, splitting the usage scenario into different questions or perhaps even into different AI assistants, or it can be solved technically by making sure the AI assistant can make multiple queries. It makes it possible to stay within the limitations of the model and at the same time ensures that nothing important is lost.
Apply specialized methods to tables and lists: Tables and long lists require extra attention, as these formats often become fragmented when documents are split into chunks. Here, correct preprocessing is necessary: tables must be extracted and structured so that headers are uniquely linked to their values. This extra preprocessing ensures that the LLM better understands the structure, which improves the quality of the answers significantly.
In a Promte assistant, we do many things to optimize how we send context to the AI model. But as a starting point it uses relatively simple RAG methods. However, we have experience with all three of the above methods to solve some of the challenges with RAG. Therefore, grab Promte if you have a good use case where more advanced methods are needed in combination with RAG to make the AI assistant work.
RAG is a powerful method for making generative AI more accurate and factually correct. But it requires being aware of both strengths and limitations. The method works best for posting single facts, where only a limited amount of information needs to be found (preferably among very large amounts of data), while complex analyzes and aggregations typically require other technologies or a combination of RAG and structured data processing tools.
At Promte, we build effective AI assistants using RAG, but we are also ready to advise when RAG should be supplemented or replaced by other solutions. We handle all the practical challenges of chunking, precise text processing, tables and citations, and our platform can be easily integrated with structured queries.
If you are interested in using AI smarter and more efficiently in your organization, contact us. We are happy to help you find the best solution for your specific needs.